Chapter XXX: Python - parsing binary data files
$Id: kurt-2010.org 13030 2010-01-14 13:33:15Z schwehr $
Table of Contents
- Introduction
- SBET - "simple" inertial navigation messages
- Read the documentation
- Initial look at an SBET file
- Opening a file and reading the data in python
- Decoding values with python's struct module
- Creating a function that reads an SBET record
- Returning data from functions
- Being able to use the whole file
- Creating a Class
- Adding iteration / looping to the Class
- Adding Google Earth KML export
- Going faster with partial reads (read(num_bytes), seek, tell)
- Going faster with mmap
- Checkpoint - what does the whole file look like here?
- Another improvement - a better iterator
- Creating a summary method
- What should __str__, __unicode__, and __repr__ return for a SBET file?
- Adding CSV export
- Adding database export
- Plotting sbet parameters
Introduction
Why learn about binary files?
Binary storage of data inside files is commonly used used over ASCII to pack data much more densely and provide much faster access. Converting ASCII to internal binary representations of data that the computer uses takes a lot of time. Additionally, it can be faster than more general packaging schemes such as Netcdf and HDF5 by being simpler.
There are many critical data sets available as binary data. However, there are often things that are wrong with the binary format that prevent you from using it in the rest of your research and data processing work. Being able to read binary data is an essential skill for people in the field you will encounter large numbers of binary formats. Being able to read these will give you valuable insight into how these systems work. For example, if you get a new version of the software on a multibeam sonar and your analysis tools start having trouble, your ability to decode the binary messages from the sonar may save you from down time or even help you to avoid collect bad data that would otherwise assume is fine if you did not look inside the messages yourself.
A warning about binary data
If you find yourself creating a new binary format for your work, please stop. There are too many formats in the world and formats like HDF5 and SQLite3 provide very powerful containers that preexisting libraries understand and these formats are self describing in that you can ask them what they store. It is difficult to create a good binary file format and you will likely make many mistakes that would be avoided. Providing clear documentation of binary file formats is extremely easy to get wrong.
As we work through several existing binary formats, I will attempt to point out what is right and wrong (in my opinion) in the design of that particular format.
What does it mean to be binary data?
FIX: write
SBET - "simple" inertial navigation messages
An SBET file is log file coming from an Applanix POSPac inertial navigation system. These devices work at a very high frequency to merge GPS, compass, gyroscopic, accelerometer, and other data that come in at a variety of time intervals. It will report its best estimate of what your air, sea, undersea, or ground vehicle is doing in terms of motion. This is the critical data that allows you to combine individual sonar pings or laser ranges to create a properly a georeferenced model of the environment.
I have taken a sample file from a research cruise in Alaska on the NOAA survey ship Fairweather. To simplify the example I have only kept every 1/10000th data message. The original file had 22 million reports and the new file has 166 reports. When learning, smaller examples are easier to work with! I will not show you how I did this, but once you have worked through this chapter, you should be able to write a python program to subsample the data exactly as I have.
Read the documentation
Applanix provides documentation for the POSPac SBET files. It is essential to look at the documentation (if it is available) before starting to parse the data. The documentation might not be perfect, but it can save you tons of time (and likely frustration).
FIX: reference the actual documentation
FIX: table of the format.
Initial look at an SBET file
Before digging in to the details of parsing with python, let's use the command line and emacs to inspect what we have. First take a look at the file sizes. I am not going to provide the original file, but I have included it here so you can see how it differs from the small sample.sbet file.
To download the file, you can save it from a web browser or pull it down in the terminal using curl or wget.
curl -O http://vislab-ccom.unh.edu/~schwehr/Classes/2011/esci895-researchtools/sample.sbet
You will just have the sample.sbet, but here I am showing you both the original and the smaller "sample.sbet":
ls -l *.sbet -rw-r--r-- 1 schwehr staff 225820248 Dec 12 09:02 original.sbet -rw-r--r-- 1 schwehr staff 22712 Dec 14 12:44 sample.sbet
It is often good to use the unix file command to see if it knows about a particular file type. Here we discover that file is not much help, but it does tell us that this is binary "data".
file *.sbet original.sbet: data sample.sbet: data
We can try to see if there is any embedded text later in the data, as file only checks a bit of the beginning of the file. The unix strings command will scan through a file and find sections that have 4 or more printable characters in a row. To avoid too much random junk that just happens to match the character codes of ASCII, we will ask string to return only matches of 6 or more characters much j
Octal dump also has a mode where it will print out the special meaning of any bytes that might have special meaning. These are things like new lines (nl), start message (stx), end message (etx), and so forth. Unfortunately, there is nothing obvious about the format. The output here is not helpful.
od -a sample.sbet | head
0000000 ## g ####t # q dc4 A ### H soh # nak ### ####?
0000020 G ####f Q ## z eot ## n ### ## ##dle # ) @
0000040 K ## # 9a * ### $ @ R # 90 83 | ####### ?
0000060 ###yn ## ## ### f ## ? esc u # etx bel 88 e #
0000100 # vt # ' ###### # ? # ### # 2 8 90 # #
0000120 z ## = can ##### ## # ### R ### $ # e ### #
0000140 ##### ### # # ## ## # stx < w u 83 ##### ?
0000160 ### B ##### ###### 95 ? m # 83 4 / # 9d ?
0000200 si { etb D ## ### { # ###ff 99 etx 84 r dc4 A
0000220 dc3 95 # ### e ### ####? #######c3 stx # z eot ##
Better yet, Octal Dump has a mode that will try to treat the file as uniform binary data (for example, a series of 4 byte integers). Since we know that our SBET file will contain a series of 17 doubles (8 bytes each) in a row, let's try out a sample file that contains the numbers 0 through 16,
od -t fD s1.bin 0000000 0.000000000000000e+00 1.000000000000000e+00 0000020 2.000000000000000e+00 3.000000000000000e+00 0000040 4.000000000000000e+00 5.000000000000000e+00 0000060 6.000000000000000e+00 7.000000000000000e+00 0000100 8.000000000000000e+00 9.000000000000000e+00 0000120 1.000000000000000e+01 1.100000000000000e+01 0000140 1.200000000000000e+01 1.300000000000000e+01 0000160 1.400000000000000e+01 1.500000000000000e+01 0000200 1.600000000000000e+01 0000210
It might look weird to you, but 1.40e+01 is actually the number 14.0. We can now try to same thing on our sbet. Each datagram has 17 fields of 8 byte doubles for a total of 168 bytes. If we want to view the first two datagrams, we can ask od to print out just up to a certain byte count with the "-n" option. Two datagrams will be be 272 bytes.
od -N 272 -t fD sample.sbet 0000000 3.349590048233234e+05 1.054952263850787e+00 0000020 -2.559965741819528e+00 1.282630055734282e+01 0000040 1.043782504645391e+01 9.982283181789831e-01 0000060 1.828280453666403e-01 -2.628339481204234e-03 0000100 1.141660305793682e-01 -9.985686530029529e-02 0000120 -4.015467392667414e-01 -8.249097558096672e-01 0000140 -3.413483211034812e-01 7.018300645653144e-02 0000160 2.132017683362876e-02 2.900003202460815e-02 0000200 -6.807197876212325e-03 3.350090035135288e+05 0000220 1.055028809795947e+00 -2.559907928689193e+00 0000240 1.272997378104385e+01 1.042404852578803e+01 0000260 1.287703038920362e+00 2.491409993943237e-01 0000300 6.418474606643030e-03 1.040782092443994e-01 0000320 -1.198332534114335e-01 -4.021915714645197e-01 0000340 8.870342742214299e-02 7.607961433375590e-02 0000360 -1.743265137730372e+00 1.903246157839654e-02 0000400 7.630558594581809e-02 3.111229241529141e-03 0000420
If we look at the first number from both datagrams, which is supposed to be a measure of time, we can see that the numbers are 3.349590048233234e+05 and 3.350090035135288e+05. It's hard to see, but it looks like time is moving slightly forward. This means we are on the right track.
It's time to switch from the terminal to python!
Opening a file and reading the data in python
There are several ways to open a file and access the data. Let's start with the simplest method. If you try this on a multi-gigabyte file, it will take a really long time, but in the case of a small test file, this is a great way to get started. Later, I will show you how to read the file a bit at a time and finally, I will show you a fancy method called mmap that can has the potential to greatly speed up your program.
First, open the file. This will return a file object back to you that you can use to read or manipulate the contents of the file.
FIX: link to python file object documentation
FIX: this does not work in python3!
sbet_file = open('sample.sbet')
There are many things you can do with a file, but in our case, we want to pull the entire file into a variable.
sbet_data = sbet_file.read() type(sbet_data) # Out: <type 'str'> len(sbet_data) # 22712
Decoding values with python's struct module
We now have 22712 bytes in a string. We can start using the python struct module to begin decoding the file. Struct is designed just for our needs - going between python and binary data. We specify letter codes and python does the hard work of figuring out how to decode the bytes from the type. However, If we specify a type different than what is actually in the data, python will happily decode the data and give us back meaningless junk. Pack goes from python to binary and unpack goes from binary to python variable types.
FIX: put in table of types
Let's give it a try on the time field. 'd' is for doubles and we want one double that takes up the first 8 bytes of the data. struct is designed to decode a whole bunch of values at the same time, so it returns the results in a tuple (unchangeable list). Note that you must pass in exactly the right number of bytes to unpack for the format codes that you give it, so we will pull a sub-array of the sbetdata array with "[0:8]".
struct.unpack('d',sbet_data[0:8]) # (334959.0048233234,) struct.unpack('d',sbet_data[0:8])[0] # 334959.0048233234
The next two fields are the latitude and longitude in radians. Let's first grab the second two values at the same time. Being the 2nd double, the latitude will start at position 8. We then at 16 bytes on to the 8 to get the stopping position of the longitude.
struct.unpack('dd',sbet_data[8:24])
(1.0549522638507869, -2.559965741819528)
Reading latitude and longitude in radians is no fun. The math module has, among many other things, functions to convert between degrees and radians. Also, if you know how many values will be returned from a function call, you can specify that many variables before the equal sign and python will put the results into each variable in order.
lat_rad, lon_rad = struct.unpack('dd',sbet_data[8:24]) math.degrees(lat_rad) # 60.444312306421736 In [36]: math.degrees(lon_rad) # -146.6752327043359
You can now go look at a map for 60.4N and 146.7W to see the area where the Fairweather was located when collecting this data.
Since we have 17 variables, it can be annoying to do either 17 struct.unpack calls or write out 17 "d" characters in a string, so struct allows you to put a number before the d to specify the number of values you would like to decode. Here is the sample latitude and longitude example, but using "2d" rather than "dd".
struct.unpack('2d',sbet_data[8:24])
(1.0549522638507869, -2.559965741819528)
We can now try decoding all 17 variables. This is not so much fun.
struct.unpack('17d',sbet_data[0:8*17])
Out[38]:
(334959.0048233234,
1.0549522638507869,
-2.559965741819528,
12.826300557342815,
10.437825046453915,
0.998228318178983,
0.18282804536664027,
-0.0026283394812042344,
0.11416603057936824,
-0.09985686530029529,
-0.40154673926674145,
-0.8249097558096672,
-0.3413483211034812,
0.07018300645653144,
0.021320176833628756,
0.029000032024608147,
-0.006807197876212325)
We can use the field names separated by commas to fill in all the variable. The "\" character allows you to continue a line of code on to the next line.
time, latitude, longitude, altitude, \
x_vel, y_vel, z_vel, \
roll, pitch, platform_heading, wander_angle, \
x_acceleration, y_acceleration, z_acceleration, \
x_angular_rate, y_angular_rate, z_angular = struct.unpack('ddddddddddddddddd',data[0:17*8])
It is really hard to follow what is going on in that last python call to unpack. Rather than list out each field name, we can have python create a dictionary with named entries for each of our values.
field_names = ('time', 'latitude', 'longitude', 'altitude', \ 'x_vel', 'y_vel', 'z_vel', \ 'roll', 'pitch', 'platform_heading', 'wander_angle', \ 'x_acceleration', 'y_acceleration', 'z_acceleration', \ 'x_angular_rate', 'y_angular_rate', 'z_angular') values = struct.unpack('17d',sbet_data[0:8*17]) # Crazy stuff happens here! dict( zip(field_names, values) )
The last command needs some explanation. First here is what it returns:
{'altitude': 12.826300557342815,
'latitude': 1.0549522638507869,
'longitude': -2.559965741819528,
'pitch': 0.11416603057936824,
'platform_heading': -0.09985686530029529,
'roll': -0.0026283394812042344,
'time': 334959.0048233234,
'wander_angle': -0.40154673926674145,
'x_acceleration': -0.8249097558096672,
'x_angular_rate': 0.021320176833628756,
'x_vel': 10.437825046453915,
'y_acceleration': -0.3413483211034812,
'y_angular_rate': 0.029000032024608147,
'y_vel': 0.998228318178983,
'z_acceleration': 0.07018300645653144,
'z_angular': -0.006807197876212325,
'z_vel': 0.18282804536664027}
That is a python dictionary with each field stored by name. You might ask how the heck that works! First the call to zip combines the list of field names and the list of values into paired entries. They have to be in exactly the same order. Here is an example with the first 4 entries in each:
zip(field_names[:4], values[:4]) # Results in: [('time', 334959.0048233234), ('latitude', 1.0549522638507869), ('longitude', -2.559965741819528), ('altitude', 12.826300557342815)]
The python dictionary can be created by a sequence of key and value pairs (often referred to as k,v). You now have a dictionary that you can work with or pass around. You can do conversions and store them back into the dictionary and only have to pass around one "thing".
sbet_values = dict(zip (field_names, values)) # convert radians to degrees and put it in a new dictionary key sbet_values['lat_deg'] = math.degrees(sbet_values['latitude']) sbet_values['lat_deg'] # 60.444312306421736
Creating a function that reads an SBET record
A stub function
Now that we have the basics of decoding a datagram down, we should turn it into a function so that we can reuse it in the future. Create a new file called sbet.py in your favorite text editor (in emacs: C-x C-f sbet.py). We are going to work on our function by using ipython to test it.
ipython
Now start off by creating a file with a "stub" function that does not do anything real. "stubs" are things that are placeholders that do not do much if anything.
# Decode Applanix POSPac SBET IMU binary files def decode(): print "hello from decode"
The above python code creates one function that is started by the "def" for define function. "decode" is the function name. All functions have an "argument list" that is in the "()". These are the variables that you will pass into the function. By having nothing in the parentheses, you are saying that the decode function does not let you pass anything to it.
As we say in the previous chapters, block or groups of code are separated by indentation. Any change of the indentation either stops or starts a block. By indenting 4 spaces, I start a new function. You can use any indentation, but 4 is the convention in the python community.
A python file can work exactly like the modules you have been using so far. Try importing it and kick the tires. With import it is important to notice that you leave off the ".py". In our case here, be sure to start ipython in the same directory as you are putting the sbet.py and sample.sbet files.
import sbet sbet.decode() # hello from decode
You now have a working module. It doesn't do much yet, but we will get there quickly. As you make changes to the python file, if you rerun the "sbet.decode()", you will find that nothing changes. You need to reload the python file into ipython with the reload command. Change the file to match what I have here:
# Decode Applanix POSPac SBET IMU binary files # You will see this when you load or reload this file, this line will print print "load or reload happening" def decode(): print "hello from decode" print 7*6
The new first print line is not inside a function. It is there to show you that anything not inside a function (or later a you will see a class), will get run immediately. This is helpful here - we can see if the reload actually happened. Try a reload in ipython. Once you have reloaded the sbet.py module, you can now use the new version of the decode function.
reload(sbet) # load or reload happening sbet.decode() # hello from decode # 42
Getting data ready to parse
Parsing means to pull apart some data or text into pieces that we can use locally. Think of writing a program to find all the words in a text document. The "parser" has to take the text and break into chunks separated by white space (new lines, space characters, or tabs) or punctuation. But before you can parse data, you need to load the data. We will use the simplest approach as described above. There are faster ways, but it is usually better to get a working program first before you try to make it go fast (call "optimizing").
We will put our controlling code into a function called "main". Functions in a module (aka python file) can come in any order, but I put my main functions at the bottom of the file. This is just my personal style.
Here is the program with the new main function that uses the open and read calls discussed previously.
# Decode Applanix POSPac SBET IMU binary files # You will see this when you load or reload this file, this line will print print "load or reload happening" def decode(): print "hello from decode" print 7*6 def main(): print 'Starting main' sbet_file = open('sample.sbet') sbet_data = sbet_file.read() print 'Finishing main'
It still doesn't do anything useful, but we are getting closer! Give it a try to make sure it works. You can see the prints at the beginning and ending of the main function.
reload(sbet) # load or reload happening In [12]: sbet.main() # Starting main # Finishing main
Now we need to pass in the data that we loaded in main to the decode function. We must add an argument to the decode function. The name of this argument has nothing to do with the name of what we pass in. What ever is passed in first will get assigned to the first argument inside the function. So here, the contents of the sbetdata variable will get assigned to the "data" variable inside the decode function.
# Add data argument to decode def decode(data): 'Decipher a SBET datagram from binary' print "hello from decode" print 'Data length:', len(data) def main(): print 'Starting main' sbet_file = open('sample.sbet') sbet_data = sbet_file.read() print 'Read this many bytes:',len(sbet_data) decode(sbet_data) # Pass in the sbet_data variable to decode print 'Finishing main'
It is also time to start doing a bit of documentation. Python has a mechanism called "doc strings". If there is a string as the first line of a file, function, class, or class method, then python considers that string as the documentation for the class. In the above example, I have added a string right after the definition of the decode function. There are two ways to ask for help from ipython: the help command and appending a ? after something:
help(sbet.decode) # Help on function decode in module sbet: # # decode(data) # Decipher a SBET datagram from binary sbet.decode? # Type: function # Base Class: <type 'function'> # String Form: <function decode at 0x11f09f0> # Namespace: Interactive # File: /Users/schwehr/Desktop/sbet/sbet.py # Definition: sbet.decode(data) # Docstring: # Decipher a SBET datagram from binary
So we have documentation, but a function that doesn't do anything. I know you are getting impatient with me, so let's actually decode the first datagram in the SBET file. Here is the new "decode" function that actually does a little bit of decoding and prints the time, latitude/longitude in degrees.
def decode(data): "Decipher a SBET datagram from binary" print "Start decoding datagram" values = struct.unpack('17d',data[0:8*17]) time = values[0] latitude = values[1] lat_deg = math.degrees(latitude) longitude = values[2] lon_deg = math.degrees(longitude) print 'results:', time, lat_deg, lon_deg
Since the decode function uses unpack from the struct library and degrees from the math library, we need to add an import statement to the top of the file. You might wonder why if we have done an import of math in ipython, why do we need it in the file? imports only work in the context of the local module or python interactive session. Each module is independent and needs to tell python which modules it needs.
# Decode Applanix POSPac SBET IMU binary files # The import must come before the decode function. # In python, the convention is to put imports at the top of the file # We can import several modules in one line by separating them with commas import math, struct # You will see this when you load or reload this file, this line will print print "load or reload happening"
We should now be able to reload the sbet module and try it out decoding actual data:
reload(sbet) # load or reload happening sbet.main() # Starting main # Read this many bytes: 22712 # Start decoding datagram # results: 334959.004823 60.4443123064 -146.675232704 # Finishing main
This is pretty exciting! We now have a file that we can use to redo a decoding. It's not very flexible, but it works. We need to work to improve it to be more useful.
The first thing to do to make it more useful is to allow it to run from the command line. We can almost do that already, but not as easily as we would like. First quit ipython and get back to the bash terminal prompt. We can tell python to run a file:
python sbet.py # load or reload happening
We need to add some special code that detects if the python is being run as a main program. There is a special trick in python to detect this case using the _name__ variable. Add this line to your sbet.py file:
print '__name__', __name__
If you import the module from ipython, _name__ will be set to the name of the module: in this case "sbet". Run ipython and import sbet.
import sbet # load or reload happening # __name__ sbet
If you exit ipython to bash, and use python to run the sbet script, you will see that _name__ has changed to _main__.
python sbet.py load or reload happening __name__ __main__
Using this, we can add a check at the bottom of sbet.py to see if it is being run as a script. If so, we can right away start up the process of getting the script going. If sbet.py is imported, the code will not run, which is what we want because it will be some other code's job to use the functions in the sbet module.
if __name__=='__main__': print 'starting to run script...' main() print 'script done!'
Then if we run the script using python from the bash prompt, it will actually call the main() function and get things going.
cd && python sbet.py # load or reload happening # __name__ __main__ # starting to run script... # Starting main # Read this many bytes: 22712 # Start decoding datagram # results: 334959.004823 60.4443123064 -146.675232704 # Finishing main # script done!
It can be really annoying to have to remember to type python before the script all the time. You don't want to be required to tell other people which language the script uses any time they want to run it. There is a special mechanism that bash uses to see how it should run a script file: it checks the first line. If that line starts with a #! ("pound bag"), then bash will use the program listed after to run the rest of the file. The trouble is that we don't know exactly where python is installed on the computer. It might be in /bin, /usr/bin, or elsewhere. Plus the person might have changed their path to point to a different version of python that works better for them. We want to honor that choice. There is a unix command called env that is supposed to always be located in the same place. It looks at the path and finds the python interpreter. This is the recommended way to create a python script. Add this line to the very beginning of your sbet.py file.
#!/usr/bin/env python
One more thing to fix. You have to tell the computer that the file is "executable". Otherwise it will not think that it can run the file. The chmod command will let you set the permissions on the sbet.py file. After chmod is run, not the extra "x" characters for executable on the left side of the return from the ls command.
ls -l sbet.py # -rw-r--r-- 1 schwehr staff 883 Dec 20 17:26 sbet.py chmod +x sbet.py ls -l sbet.py # -rwxr-xr-x 1 schwehr staff 883 Dec 20 17:26 sbet.py
Now you can run your sbet.py script without knowing that it is python inside.
./sbet.py # load or reload happening # __name__ __main__ # starting to run script... # Starting main # Read this many bytes: 22712 # Start decoding datagram # results: 334959.004823 60.4443123064 -146.675232704 # Finishing main # script done!
Before we go any farther, let's clean up the file and give it a look over. I have deleted extra print statements.
#!/usr/bin/env python # Decode Applanix POSPac SBET IMU binary files import math, struct def decode(data): "Decipher a SBET datagram from binary" values = struct.unpack('17d',data[0:8*17]) time = values[0] latitude = values[1] lat_deg = math.degrees(latitude) longitude = values[2] lon_deg = math.degrees(longitude) print 'results:', time, lat_deg, lon_deg def main(): sbet_file = open('sample.sbet') sbet_data = sbet_file.read() decode(sbet_data) if __name__=='__main__': main()
Now let's change the decode function to get all of the fields as we did before. I am going to use the dict and zip method before, but if you are writing your own decoder for something else, you can certainly decode each field individually. Add the fieldnames to your file before the decode function and change decode to look like this:
field_names = ('time', 'latitude', 'longitude', 'altitude', \ 'x_vel', 'y_vel', 'z_vel', \ 'roll', 'pitch', 'platform_heading', 'wander_angle', \ 'x_acceleration', 'y_acceleration', 'z_acceleration', \ 'x_angular_rate', 'y_angular_rate', 'z_angular') def decode(data): "Decipher a SBET datagram from binary" values = struct.unpack('17d',data[0:8*17]) # Create a dictionary for all the values sbet_values = dict(zip (field_names, values)) sbet_values['lat_deg'] = math.degrees(sbet_values['latitude']) sbet_values['lon_deg'] = math.degrees(sbet_values['longitude']) print 'results:' for key in sbet_values: print ' ', key, sbet_values[key]
I have change the printing of the result at the end to be easier to read. If we just print a dictionary, it will be a big mush. However, looping over a dictionary with a for loop will return the keys of the dictionary one by one. Try running the resulting program.
./sbet.py # results: # x_acceleration -0.82490975581 # x_angular_rate 0.0213201768336 # platform_heading -0.0998568653003 # y_angular_rate 0.0290000320246 # pitch 0.114166030579 # altitude 12.8263005573 # z_vel 0.182828045367 # lat_deg 60.4443123064 # longitude -2.55996574182 # roll -0.0026283394812 # y_vel 0.998228318179 # y_acceleration -0.341348321103 # time 334959.004823 # latitude 1.05495226385 # lon_deg -146.675232704 # z_acceleration 0.0701830064565 # z_angular -0.00680719787621 # x_vel 10.4378250465 # wander_angle -0.401546739267
Returning data from functions
Really, when programming, it is a bad idea to mix the logic and data handling with the "view" or output of the program. What if you want to parse a datagram, but have no need to print it? We should split the printing part into a separate program, but that means our decode function needs to return back what it figured out so we can pass it on.
We need to change the main to look like this:
def main(): sbet_file = open('sample.sbet') sbet_data = sbet_file.read() datagram = decode(sbet_data) sbet_print(datagram)
To get the datagram information back from the decode function. The way to do that is to "return" the dictionary sbetvalues back at the end of the decode and to remove the printing.
def decode(data): "Decipher a SBET datagram from binary" values = struct.unpack('17d',data[0:8*17]) # Create a dictionary for all the values sbet_values = dict(zip (field_names, values)) sbet_values['lat_deg'] = math.degrees(sbet_values['latitude']) sbet_values['lon_deg'] = math.degrees(sbet_values['longitude']) return sbet_values # Send the sbet_values dictionary back to the caller
Then we need to take that printing code from before and make a function for it. I would use "print" as the function name, but that is already taken by python's print, so I will call it sbetprint.
def sbet_print(sbet_values): 'Print out all the values of a SBET dictionary' print 'results:' for key in sbet_values: print ' ', key, sbet_values[key]
We haven't done anything to how the script looks when it is run, but now we have a program that is a little bit more flexible. However, we now have the problem that we can only decode the first datagram.
Being able to use the whole file
It would be nice to be able to decode any datagram from the file that we would like. First, we need to modify the decode function to know where the datagram starts in the data. We can pass in a second argument to decode that tells it how far into the data we want it to look for the datagram. This is commonly referred to as the offset. We can also tell python that if decode is called without an offset, it is okay to start at the beginning of the file. This is done by setting offset to the default value of 0.
def decode(data, offset=0): '''Decipher a SBET datagram from binary''' # Offset now tells it how far to start values = struct.unpack('17d',data[ offset + 0 : offset + 8*17 ]) # Create a dictionary for all the values sbet_values = dict(zip (field_names, values)) sbet_values['lat_deg'] = math.degrees(sbet_values['latitude']) sbet_values['lon_deg'] = math.degrees(sbet_values['longitude']) return sbet_values
Now we need to know how many datagrams are in the file and where each datagram starts. We need some "helper" functions to capture our knowledge of datagrams in the file. First, we need a function that will tell us how many datagrams are in file. We know that there are 17 parameters in a datagram and each one is 8 bytes long because the are double precision floating point numbers for a total of 136 bytes. We can save the datagramsize as a variable and we will not have to remember the size. We use an assert to check the size of data. To do this use the remainder (also known as "mod") operator: "%". We have to make sure that the remainder is always zero or we have a problem. After that, we can then divide the length of data by the size of each datagram.
def num_datagrams(data): 'How many packets are in data' # Make sure we have an even number of datagrams assert (len(data) % datagram_size == 0) return len(data) / datagram_size
We can then modify the main function to print out just the total number of datagrams.
def main(): sbet_file = open('sample.sbet') sbet_data = sbet_file.read() print 'Number of datagrams:', num_datagrams(sbet_data)
The results of running the program now tell us something about the overall file.
./sbet.py # Number of datagrams: 167
The next thing we need is a function that, given a datagram number, tells us the offset for that datagram. We can then pass that offset to the decode function.
def get_offset(datagram_number): 'Calculate the starting offset of a datagram' return datagram_number * datagram_size
Give it a test with ipython.
import sbet sbet.get_offset(10) # 1360
Now, in our main function, we can loop through each datagram index, calculate the offset to the datagram in the data variable, decode the datagram and print one line of summary data. The python range function will return a list starting at 0 and going up to the number given minus 1. Here, we have 167 datagrams, so range will return 0 to 166.
def main(): sbet_file = open('sample.sbet') sbet_data = sbet_file.read() print 'Number of datagrams:', num_datagrams(sbet_data) print 'Datagram Number, Time, x, y' for datagram_index in range( num_datagrams(sbet_data) ): offset = get_offset(datagram_index) datagram = decode(sbet_data,offset) print datagram_index, datagram['time'],datagram['lon_deg'], datagram['lat_deg']
Now, if we run the sbet.py script, it should tell us about the overall file!
./sbet2.py Number of datagrams: 167 Datagram Number, Time, x, y 0 334959.004823 -146.675232704 60.4443123064 1 335009.003514 -146.671920256 60.448698066 2 335059.002204 -146.667715067 60.4528836831 3 335109.000894 -146.663165536 60.4570416942 4 335158.999585 -146.659085911 60.4612950577 5 335208.998275 -146.654515522 60.4654683305 6 335258.996965 -146.650207253 60.4696697568 7 335308.995656 -146.645977489 60.473902636 8 335358.994346 -146.641281066 60.4779957167 9 335408.993037 -146.638941903 60.480409512 10 335458.991726 -146.631176844 60.4833850599 11 335508.990417 -146.621642293 60.485327861 ... # deleted lots of lines 159 342908.796619 -146.666329194 60.458063574 160 342958.795311 -146.669429917 60.4556509106 161 343008.794001 -146.672748828 60.4530355694 162 343058.792691 -146.676103126 60.4503613441 163 343108.791383 -146.680134497 60.4470974834 164 343158.790073 -146.684515778 60.4438300029 165 343208.788763 -146.688333227 60.4404511588 166 343258.787453 -146.692187946 60.4370705138
To make sure you are all caught up, here is the entire sbet.py file as I have it now. It's up to 63 lines.
#!/usr/bin/env python # Decode Applanix POSPac SBET IMU binary files import math, struct field_names = ('time', 'latitude', 'longitude', 'altitude', \ 'x_vel', 'y_vel', 'z_vel', \ 'roll', 'pitch', 'platform_heading', 'wander_angle', \ 'x_acceleration', 'y_acceleration', 'z_acceleration', \ 'x_angular_rate', 'y_angular_rate', 'z_angular') def decode(data, offset=0): '''Decipher a SBET datagram from binary''' # Offset now tells it how far to start values = struct.unpack('17d',data[ offset + 0 : offset + 8*17 ]) # Create a dictionary for all the values sbet_values = dict(zip (field_names, values)) sbet_values['lat_deg'] = math.degrees(sbet_values['latitude']) sbet_values['lon_deg'] = math.degrees(sbet_values['longitude']) return sbet_values def sbet_print(sbet_values): 'Print out all the values of a SBET dictionary' print 'results:' for key in sbet_values: print ' ', key, sbet_values[key] datagram_size = 136 # 8*17 bytes per datagram def num_datagrams(data): 'How many packets are in data' # Make sure we have an even number of datagrams assert (len(data) % datagram_size == 0) return len(data) / datagram_size def get_offset(datagram_number): 'Calculate the starting offset of a datagram' return datagram_number * datagram_size def main(): sbet_file = open('sample.sbet') sbet_data = sbet_file.read() print 'Number of datagrams:', num_datagrams(sbet_data) print 'Datagram Number, Time, x, y' for datagram_index in range( num_datagrams(sbet_data) ): offset = get_offset(datagram_index) datagram = decode(sbet_data,offset) print datagram_index, datagram['time'],datagram['lon_deg'], datagram['lat_deg'] if __name__=='__main__': main()
Creating a Class
See also: Dive into Python's 5.3. Defining Classes and Python.org's Classes
Before we go adding lots of other features, it is time to clean up the handling of sbet files. In python, we can wrap the handling of an sbet file into a Class. For each sbet file that we work with, a class will create an object that can keep track of what we are doing with the sbet file as a thing. We can ask the thing to print itself, get the next datagram, etc. This is where we get to objected oriented programming (OOP). Don't worry what that is right now. You will learn by doing and start to get a feel for it as you see more examples in use. Start a new file called "sbet2.py". Enter this in and then I will walk you through what is here.
#!/usr/bin/env python class Sbet(object): def __init__(self): print type(self) def main(): sbet = Sbet() if __name__ == '__main__': main()
Now, make that file executable and give it a run.
chmod +x sbet2.py ./sbet2.py # <class '__main__.Sbet'>
Let's start with the 3 lines starting with class. A class is a collection of functions, but when they are part of a class, they are termed methods. Class names by convention in python start with a capital letter. The "(object)" says that the Sbet class will get capabilities of the default python object. For now, just assume that it is required text for all your classes.
There are a number of special methods that start and end with two underscores ("__"). The first one is __init__. It is called when you create a new object of type Sbet and is called to handle "instantiation" of the instance of the Class. Confusing terminology, I know. You create an object like this:
my_sbet = Sbet()
By running the program, you create an instance of an 'Sbet' Class. The __init__ gets called. The first argument to all methods in a class will be a copy of the object. In other languages, it might be called "this", but "self" is the convention in python. The "print type(self)" returned a string of "<class '__main__.Sbet'>"
You can store data in self and __init__ is the time to get things setup for later processing. We need to get the sbet file opened, read the data, and figure out how many datagrams are around. Here is how I would do that. While I am rewriting the previous code as a class, I am going to make it more flexible. The __init__ can take extra arguments, so it is time to pass in the name of the sbet file. Hard coding file names like we did before is great for quick development, but it is bad to leave it in your code over the long run. I have moved the filename into the main function.
class Sbet(object): def __init__(self, filename): sbet_file = open(filename) self.data = sbet_file.read() # Make sure the file is sane assert(len(self.data)%datagram_size == 0) self.num_datagrams = len(self.data) / datagram_size def main(): sbet = Sbet('sample.sbet')
Now we can start adding methods to the class to help us out. The first one we need is to bring back the decode method. That's pretty important. We will have to bring back the imports of math and struct. Additionally, I will use the fieldnames tuple (remember parentheses are for tuples and square brackets are lists), so put it into this new file. And add a call in main to the decode method on our lowercase sbet object.
import math, struct datagram_size = 136 field_names = ('time', 'latitude', 'longitude', 'altitude', \ 'x_vel', 'y_vel', 'z_vel', \ 'roll', 'pitch', 'platform_heading', 'wander_angle', \ 'x_acceleration', 'y_acceleration', 'z_acceleration', \ 'x_angular_rate', 'y_angular_rate', 'z_angular') class Sbet(object): def __init__(self, filename): sbet_file = open(filename) self.data = sbet_file.read() # Make sure the file is sane assert(len(self.data)%datagram_size == 0) self.num_datagrams = len(self.data) / datagram_size def decode(self, offset=0): 'Return a dictionary for an SBet datagram starting at offset' values = struct.unpack('17d',self.data[ offset : offset+datagram_size ]) sbet_values = dict(zip (field_names, values)) sbet_values['lat_deg'] = math.degrees(sbet_values['latitude']) sbet_values['lon_deg'] = math.degrees(sbet_values['longitude']) return sbet_values
Notice that when I call struct.unpack, I passed it "self.data" instead of data. "self.data" goes back to the data that we saved back in the __init__ method. Give it a try:
./sbet2.py # {'x_acceleration': -0.8249097558096672, 'x_angular_rate': # 0.021320176833628756, 'platform_heading': -0.09985686530029529, # 'y_angular_rate': 0.029000032024608147, 'pitch': 0.11416603057936824, # 'altitude': 12.826300557342815, 'z_vel': 0.18282804536664027, # 'lat_deg': 60.444312306421736, 'longitude': -2.559965741819528, # 'roll': -0.0026283394812042344, 'y_vel': 0.998228318178983, # 'y_acceleration': -0.3413483211034812, 'time': 334959.0048233234, # 'latitude': 1.0549522638507869, 'lon_deg': -146.6752327043359, # 'z_acceleration': 0.07018300645653144, 'z_angular': # -0.006807197876212325, 'x_vel': 10.437825046453915, 'wander_angle': # -0.40154673926674145}
We also would like to be able to get packets by index again, but it would be nice to do that without having to think about the decode method and offsets. We should add a "getdatagram" method that takes the datagram's index number.
def get_offset(self, datagram_index): return datagram_index * datagram_size def get_datagram(self, datagram_index): offset = self.get_offset(datagram_index) values = self.decode(offset) return values
Using what we have, we can recreate printing out a summary of the ship navigation in main.
def main(): sbet = Sbet('sample.sbet') print 'Datagram Number, Time, x, y' for index in range(sbet.num_datagrams): datagram = sbet.get_datagram(index) print index, datagram['time'],datagram['lon_deg'], datagram['lat_deg']
The results of this look just like before, but the python code is getting cleaner.
./sbet2.py # len_data: 22712 # Datagram Number, Time, x, y # 0 334959.004823 -146.675232704 60.4443123064 # 1 335009.003514 -146.671920256 60.448698066 # 2 335059.002204 -146.667715067 60.4528836831 # 3 335109.000894 -146.663165536 60.4570416942 # 4 335158.999585 -146.659085911 60.4612950577 # 5 335208.998275 -146.654515522 60.4654683305 # 6 335258.996965 -146.650207253 60.4696697568 # 7 335308.995656 -146.645977489 60.473902636 # ...
Adding iteration / looping to the Class
See also: Dive into Python's Classes & Iterators
Python has a convention for making looping or "iteration" to be built into classes. This tries to simplify your overall code. For example, for loops should not have to keep track of the datagram index. Python does this for classes when you add two special methods: __iter__ and next. Note: In python 2, it is just "next", python 3 uses __next__.
__iter__ is the call that starts the iteration. We in this function, we need to record where we are in the data - starting at position 0. We then return the self back to the caller (e.g. the for loop). There are times when you want the iteration to be handled outside the class.
Then in the next method, we have to check to see if we have reached the end. Python has a concept called exceptions that are useful for unusual events. Here the raise throws an exception of type StopIteration. This triggers the looping to end.
def __iter__(self): 'start iteration' self.iter_position = 0 return self def next(self): 'Take the next step in the iteration' if self.iter_position >= self.num_datagrams: raise StopIteration values = self.get_datagram(self.iter_position) self.iter_position += 1 return values
Now we need to simplify our main function. The sbet object now can be iterated by a for loop. Each time through the for loop, the values that were returned in the next method get put into the datagram variable.
def main(): print 'Datagram Number, Time, x, y' sbet = Sbet('sample.sbet') for datagram in sbet: print datagram['time'],datagram['lon_deg'], datagram['lat_deg']
That's definitely simpler, but we have lost the count of the datagram. enumerate is a special function that takes an iteratable object and returns each element with a count before it. We can then just loop through the sbet and not worry about which datagram we are at.
sbet = Sbet('sample.sbet') for index, datagram in enumerate(sbet): print index, datagram['time'], datagram['lon_deg'], datagram['lat_deg']
It runs just like before:
./sbet2.py | head # Datagram Number, Time, x, y # 0 334959.004823 -146.675232704 60.4443123064 # 1 335009.003514 -146.671920256 60.448698066 # 2 335059.002204 -146.667715067 60.4528836831 # 3 335109.000894 -146.663165536 60.4570416942 # 4 335158.999585 -146.659085911 60.4612950577 # 5 335208.998275 -146.654515522 60.4654683305 # 6 335258.996965 -146.650207253 60.4696697568 # 7 335308.995656 -146.645977489 60.473902636 # 8 335358.994346 -146.641281066 60.4779957167 # ...
Adding Google Earth KML export
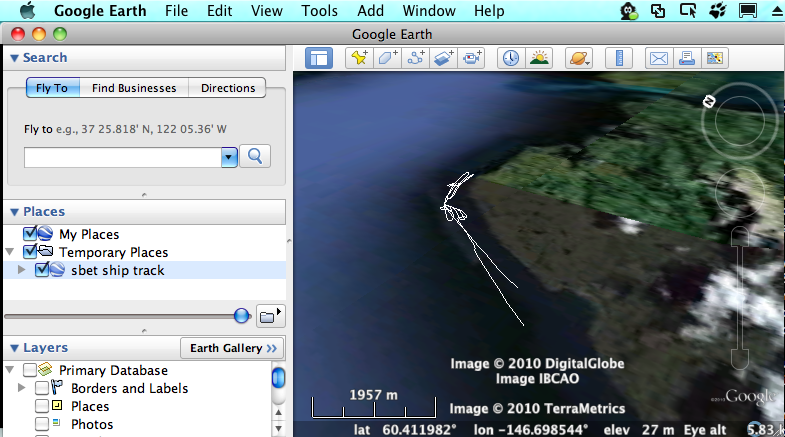
It's time to add a first try at a Google Earth KML export.
First, here is an example of a line with three points in KML. KML is a form of the Extensible Markup Language (XML). The key to XML is that everything in the file starts with a beginning tag (e.g. "<tag>") and finishes with a matching end tag (e.g. "</tag>"). You will see a large number of angle brackets in XML files. Do not worry too much about the details of XML and KML. The key thing to observe is that there is a "<coordinates> </coordinates>" block that contains longitude and latitude pairs (e.g. x,y). Be careful that you don't do y,x (aka lat, lon).
<?xml version="1.0" encoding="UTF-8"?> <kml xmlns="http://earth.google.com/kml/2.1"> <Document> <name>sbet ship track</name> <Placemark> <name>sbet line</name> <LineString> <coordinates> -146.675232704,60.4443123064 -146.671920256,60.448698066 -146.667715067,60.4528836831 </coordinates> </LineString> </Placemark> </Document> </kml>
If you save that KML into a file called "test.kml" and open it in Google Earth, you will see that the program will fly to Alaska and show you a very short line.
We now want to write KML will all of the points in an SBET from our Sbet python class. We do this by splitting the task into three sections. First we add the KML from the beginning line to the "<coordinates>" tag. Next, we will add all of the x,y points for the sbet datagrams one line at a time. Finally, we will add the text for "</coordinates>" to the final "</kml>".
Let's add a new "kml" method to our Sbet class.
def kml(self): out_str = '' return out_str
The design of our kml function is that it will return a string with the KML in it. In python, the "+=" operator appends a string on to an existing string (aside: it creates a new longer string and assigns it to the old variable name). Also the triple quote ( *'''* ) allows for strings that span multiple lines. We can now write the header.
def kml(self): out_str = '' out_str += '''<?xml version="1.0" encoding="UTF-8"?> <kml xmlns="http://earth.google.com/kml/2.1"> <Document> <name>sbet ship track</name> <Placemark> <name></name> <LineString> <coordinates> ''' return out_str
The out_str ( "output string" ) variable will now return the first part of the KML. We can now use a for loop iterator like we did before to get all the coordinates. After we add the for loop, we can also add the footer to finish the KML.
def kml(self): out_str = '' out_str += '''<?xml version="1.0" encoding="UTF-8"?> <kml xmlns="http://earth.google.com/kml/2.1"> <Document> <name>sbet ship track</name> <Placemark> <name></name> <LineString> <coordinates> ''' for datagram in self: out_str += str(datagram['lon_deg']) + ',' + str(datagram['lat_deg']) + '\n' out_str += ''' </coordinates> </LineString> </Placemark> </Document> </kml>''' return out_str
That gives a compete KML generation method, but it won't go anywhere until we use it. Let's change the main() function to get the KML string and write it to a file.
def main(): sbet = Sbet('sample.sbet') # Open a new file called "sample.kml" # If the file exists it will be overwritten out = open('sample.kml','w') out.write(sbet.kml())
If you run sbet2.py, you should now see a sample.kml file. On the mac, you can use the open command to view the new KML file with the ship track.
./sbet.py ls -l sample* # -rw-r--r-- 1 schwehr staff 5203 Dec 23 17:34 sample.kml # -rw-r--r-- 1 schwehr staff 22712 Dec 14 09:44 sample.sbet open sample.kml
Going faster with partial reads (read(num_bytes), seek, tell)
Our sample file is small, but if we were working on a typical SBET file, it would be hundreds of megabytes or bigger. Reading all that data into memory at one time is not very efficient.
FIX: write an example with read and demonstrate seek and tell.
Going faster with mmap
Most people will try to switch their code to using partial read*s combined with *seek and tell commands to step through the file. The problem is that, there is a lot of copying of data going on when the data is read in.
Now: REMOVE your code that does partial reads. You can save it somewhere, but we will not use it.
Modern operating systems have a special concept called a "memory map" or "mmap". This style of loading data lets the operating system work with python rather than have python copy everything into local storage. The operating system can load and unload the data behind the scenes as needed and the data in the file magically appears in the programs memory. Only data that is needed is paged into RAM from the disk. mmap is weird to use, but you can hide it in the class.
One word of caution! If you are using a 32-bit operating system, you may run into troubles with reading files bigger than 2 GB and you will definitely have problems with files bigger than 4 GB. This comes from a limitation of being able to address that much memory at one time. The best solution to get around the problem is to upgrade to a 64-bit operating system (and make sure you are using a 64-bit version of python). If that is not possible, you will need to break your file into 2GB or smaller files.
See also: http://docs.python.org/library/mmap.html
mmap.mmap(fileno, length[, tagname[, access[, offset]]])
We have to use a "fileno", which is a number that identifies our open file and the length of the file. We also want to specify the access control and tell mmap that we want to open the file as "read-only". That way we can't accidentally modify the file. Our new initializer looks like this:
def __init__(self, filename): sbet_file = open(filename) sbet_size = os.path.getsize(filename) self.data = mmap.mmap(sbet_file.fileno(), sbet_size, access=mmap.ACCESS_READ) assert(len(self.data)%datagram_size == 0) self.num_datagrams = len(self.data) / datagram_size
Python makes it easy to switch between either style at run time, so I have made the mmap style of loading the data be the default with the argument use_mmap that defaults to True.
def __init__(self, filename, use_mmap=True): sbet_file = open(filename) if use_mmap: sbet_size = os.path.getsize(filename) self.data = mmap.mmap(sbet_file.fileno(), sbet_size, access=mmap.ACCESS_READ) else: self.data = sbet_file.read() assert(len(self.data)%datagram_size == 0) self.num_datagrams = len(self.data) / datagram_size
Checkpoint - what does the whole file look like here?
FIX: insert a python file that matches all that was done above.
Another improvement - a better iterator
Before we add more features to the class, we need to improve the iterator. The trouble with our current design is that there can only be one iterator at a time. Each iterator should be independent so that programmers do not have to worry about stepping on their own tows if they need to loop over all or part of the file. The way to do this is to pull the iterator out of the Sbet class and have a separate iterator class that handles looping over the datagrams in an Sbet object.
At this point, I am going to start over in a new file called sbet3.py. Here is the whole file rewritten to have a separate iterator class.
#!/usr/bin/env python import math, struct import os, mmap datagram_size = 136 field_names = ('time', 'latitude', 'longitude', 'altitude', \ 'x_vel', 'y_vel', 'z_vel', \ 'roll', 'pitch', 'platform_heading', 'wander_angle', \ 'x_acceleration', 'y_acceleration', 'z_acceleration', \ 'x_angular_rate', 'y_angular_rate', 'z_angular') class Sbet(object): def __init__(self, filename, use_mmap=True): sbet_file = open(filename) if use_mmap: sbet_size = os.path.getsize(filename) self.data = mmap.mmap(sbet_file.fileno(), sbet_size, access=mmap.ACCESS_READ) else: self.data = sbet_file.read() # Make sure the file is sane assert(len(self.data)%datagram_size == 0) self.num_datagrams = len(self.data) / datagram_size def decode(self, offset=0): 'Return a dictionary for an SBet datagram starting at offset' subset = self.data[ offset : offset+ datagram_size ] values = struct.unpack('17d', subset) sbet_values = dict(zip (field_names, values)) sbet_values['lat_deg'] = math.degrees(sbet_values['latitude']) sbet_values['lon_deg'] = math.degrees(sbet_values['longitude']) return sbet_values def get_offset(self, datagram_index): return datagram_index * datagram_size def get_datagram(self, datagram_index): offset = self.get_offset(datagram_index) values = self.decode(offset) return values def __iter__(self): return SbetIterator(self) class SbetIterator(object): 'Independent iterator class for Sbet files' def __init__(self,sbet): self.sbet = sbet self.iter_position = 0 def __iter__(self): return self def next(self): if self.iter_position >= self.sbet.num_datagrams: raise StopIteration values = self.sbet.get_datagram(self.iter_position) self.iter_position += 1 return values def main(): print 'Datagram Number, Time, x, y' sbet = Sbet('sample.sbet') for index, datagram in enumerate( Sbet('sample.sbet') ): print index, datagram['time'], datagram['lon_deg'], datagram['lat_deg'] if __name__ == '__main__': main()
FIX: walk through how the SbetIterator class works
- keep a reference to the sbet object
- set the datagram index ( "iter_position" ) to the beginning of the file
- Loop through the file in __next__ and throw the exception "StopIteration" when it gets to the end of the file
Creating a summary method
What should __str__, __unicode__, and __repr__ return for a SBET file?
Adding CSV export
Adding database export
Plotting sbet parameters
Date: $Date: $
HTML generated by org-mode 7.3 in emacs 23